ICU message format: Guide to plurals, dates & localization syntax

ICU message format is the standard way developers handle plurals, dates, numbers, and other localized text in software. It's part of the internationalization (i18n) toolkit that ensures your messages are grammatically correct, culturally accurate, and easy to translate — no matter the language or region. ICU is one of the core technical topics covered in our complete technical guide to internationalization and software localization, alongside locale detection, RTL layouts, and i18n architecture patterns. By using ICU, you can avoid common localization bugs like "1 rooms", "0 rooms" instead of "No rooms", or incorrect date formats, while keeping translations consistent across all platforms.
Used by Google, Microsoft, and countless frameworks like React Intl and Angular, ICU allows you to define all variations of a message in one place, making life easier for both developers and translators.
Quick start: ICU in one minute
Here's an ICU message format example that handles plurals:
// Message
"Hi, thank you for booking {bookedRooms, plural, one {room} other {rooms}} with us!"
// Result
"Hi, thank you for booking 1 room with us!"
// or
"Hi, thank you for booking 3 rooms with us!"
Why this matters for localization
- Plural rules are applied automatically for each locale.
- Translators see all variations in one place, so no missing forms.
- The same syntax works for dates, numbers, gender forms, and more.
Want to learn ICU step-by-step? Scroll down for syntax, examples and localization tips.
What is ICU?
International Components for Unicode (ICU) is an open-source, cross-platform library that supports Unicode and global text handling.
ICU is widely used in software development to ensure that applications can work with text in multiple languages, formats, and scripts, supporting different format numbers, dates, times, currencies, and other locale-sensitive data.
Created in 1999 by Taligent (later acquired by IBM), ICU was designed to address the complexity of building software for multiple languages and cultural rules. Today, it's used by Google, Microsoft, Amazon, Apple, Oracle, Adobe, and many others.
How does it work?
ICU provides APIs and data to convert, search, compare, and format text in any supported language. By combining Unicode (a universal text encoding system) with ICU's locale data, you can build applications that adapt naturally to any script or writing system.
ICU covers all text and language related issues like:
- date and time formatting
- number formatting
- currency formatting
- pluralization
- gender-specific forms
- custom variables
- sorting and searching text
Download ICU from GitHub repository and read the documentation.
Problems ICU solves
Without ICU, localization is harder and error-prone:
- Hard-coded plurals (“1 rooms” problem)
- Date/number formats that confuse users
- Gender-specific language errors
- Inconsistent translation files
ICU solves these issues by providing a standardized way to handle text formatting, pluralization, and other language-specific features. It allows developers to create messages that adapt to the user's locale, ensuring that translations are accurate and culturally appropriate.
Check our blog on best practices for software localization for more tips on how to improve your i18n process and localization quality.
What is Locale?
Locale defines the user's language, region, and cultural conventions. It is used to format and display text, dates, numbers, and other data in a way that is appropriate for a specific region or culture. For example, the date format and currency symbol used in the United States is different from that used in Spain.
Locale affects:
- Date and time formats
- Number and currency style
- Text sorting and comparison rules
It differs from the Language which is a more general term that refers to the language itself, without any specific regional or cultural context. For example, "English" is a language, while "en_US" is a locale that specifies English as spoken in the United States.
For detailed resources check ICU documentation for Locale and our blog post about differences between language and locale.
ICU Messages Formatting syntax
Messages are user-visible texts that may contain both static text and variable elements (names, dates, numbers, etc.). ICU's MessageFormat class uses curly braces { } for variables, with optional formatting instructions.
General pattern:
{variable, type, format}
variableis the name of the variable to be formattedtypespecifies the type of formatting (e.g.,date,number,plural,select)formatis the specific style or rule to be applied to the variable
ICU variables
In ICU, variables let you insert dynamic content,like numbers, dates, or names, into messages. They are defined with the MessageFormat class, which makes translations adapt to different conditions.
A simple variable without formatting works for fixed grammar, but can break in other languages:
"Hi, thank you for booking {roomsNumber} rooms with us!"
// 1 rooms ❌
To handle grammar rules such as plurals, you can add ICU formatting directly to the variable:
"Hi, thank you for booking {bookedRooms, plural, one {room} other {rooms}} with us!"
// 1 room ✅
// 3 rooms ✅
This ensures messages follow language rules for every locale.
Plurals
Pluralization rules vary depending on the language, and its grammar. The rules are different in English, Polish, or Arabic - for different locales.
For example, English has two forms: one and other.
Polish adds few and sometimes more, while Arabic has even more variations.
You can explore each language's rules in the Unicode CLDR specs.
In ICU, the plural argument selects the correct sub-message based on a number and the locale's plural rules.
Syntax for plural messages is:
{variable, plural, forms}
Where forms are the plural categories for that language.
Example in English and Polish:
// English
"You have booked {bookedRooms, plural,
one {one room},
other {# rooms}
} for {stayDate, date, medium}"
// Polish
"Zarezerwowałeś {bookedRooms, plural,
one {jeden pokój},
few {# pokoje},
other {# pokoi}
} na {stayDate, date, medium}"
Tip: The
otherform is always required, it's your fallback for unexpected values.
This format gives translators all plural cases for a language, ensuring accuracy in every locale.
Select
The ICU select format lets you choose different message variants based on the value of a variable, typically a string or keyword. This is useful for handling cases like gender, status, or other categorical data where the message changes depending on the value.
The syntax looks like this:
{variable, select,
value1 {Message for value1}
value2 {Message for value2}
other {Default message}
}
Example:
"Thank you for booking {bookedRoom, select,
dorm {a bed in dorm room}
private {a private room}
other {a room}
} in our hostel."
- if
bookedRoomisdorm, it shows "a bed in dorm room" - if
bookedRoomisprivate, it shows "a private room" - if
bookedRoomis anything else, it defaults to "a room"
Combining plurals and select
ICU messages let you combine plural and select formats to handle complex variations in your messages based on multiple variables.
For complex cases, nest plural inside select (recommended order).
To visualize the nesting structure, think of it as a decision tree:
gender (select)
├── female
│ └── num_guests (plural)
│ ├── =0 → "... doesn't invite guests to her ..."
│ ├── =1 → "... invites {guest} to her ..."
│ ├── =2 → "... invites {guest} and one other ... to her ..."
│ └── other → "... invites {guest} and # others ... to her ..."
├── male
│ └── num_guests (plural)
│ ├── =0 → "... doesn't invite guests to his ..."
│ └── ... (same structure)
└── other
└── num_guests (plural)
└── ... (uses "their")
The outer select picks the gender branch first, then the inner plural picks the correct guest count message. Here's the full example:
"{gender, select,
female {
{num_guests, plural, offset:1
=0 {{host} doesn't invite guests to her new hotel opening.}
=1 {{host} invites {guest} to her new hotel opening.}
=2 {{host} invites {guest} and one other guest to her new hotel opening.}
other {{host} invites {guest} and # other guests to her new hotel opening.}
}
}
male {
{num_guests, plural, offset:1
=0 {{host} doesn't invite guests to his new hotel opening.}
=1 {{host} invites {guest} to his new hotel opening.}
=2 {{host} invites {guest} and one other guest to his new hotel opening.}
other {{host} invites {guest} and # other guests to his new hotel opening.}
}
}
other {
{num_guests, plural, offset:1
=0 {{host} does not give a party.}
=1 {{host} invites {guest} to their new hotel opening.}
=2 {{host} invites {guest} and one other guest to their new hotel opening.}
other {{host} invites {guest} and # other guests to their new hotel opening.}
}
}
}"
It shows how to handle complex messages with multiple variables:
- Use
selectfor gender-specific forms (her/his/their). - Use
pluralfor different numbers of guests. - Nest these formats to cover all variations in one message.
This structure keeps messages clear and easy to translate, even for complicated cases.
Number formatting
The way numbers are formatted can vary depending on the language and country. It applies to different aspects of displaying numerical values, like:
- decimal formatting (thousand separator, rounding)
- currencies
- measurement units
- percentages (placement of the % symbol)
- scientific notations
- compact notation
ICU provides a powerful way to format numbers using the NumberFormat class, which allows you to format numbers according to the conventions of a specific locale.
Syntax:
{variable, number, format}
Where format covers all number formats.
Common ICU NumberFormat formats are integer, currency and percent.
12999.99 // Decimal number
$12999.99 // US currency
12 999,99zł // Polish currency
12999% // Percent
For more examples, details, and tips regarding number formatting, check Jakub's blog post about number formatting in JavaScript.
Note: ICU uses the Unicode CLDR data to provide locale-specific number formatting rules. This means that the same number can be formatted differently depending on the user's locale settings.
Date and Time Formatting
Date and time formats vary widely across countries. They differ in separators, order, and the way days, months, and years are displayed.
For example, most European countries use the format DD/MM/YYYY, while in the US and Canada, MM/DD/YYYY is common. So, September 2nd, 2023 can be written as either 02/09/2023 or 09/02/2023. This difference can confuse users if your software doesn't adjust to their local conventions. That's why localizing date and time formats properly is essential for international applications.
See the ICU date symbols table for all date patterns and syntax.
In ICU, the DateFormat class formats dates and times according to the rules of a specific locale. It is an abstract base class used for this purpose.
Syntax:
{variable, date, format}
{variable, time, format}
Where format is the specific date or time format you want to use.
ICU offers four standard date formats:
short, e.g., 2/9/23medium, e.g., Sept. 2nd, 2023long, e.g., September 2nd, 2023full, e.g., Saturday, September 2nd, 2023 AD
For time, ICU provides these default formats:
short: 9:30 AMlong: 9:30:28 AMfull: 9:30:28 AM CET
Here's an example of date formatting in action:
// Message
"Your room {roomNumber} is ready for check-in on {checkinDate, date, medium}."
// Result
"Your room 5 is ready for check-in on March 2, 2023."
Relative time formatting
Modern users expect time expressed naturally, e.g., "3 minutes ago", "yesterday", or "in 2 hours", rather than raw dates. ICU supports relative time formatting through the Intl.RelativeTimeFormat API in JavaScript and equivalent classes in other languages.
You can also use the select syntax for common relative-day labels:
"{days, select, -1 {yesterday} 0 {today} 1 {tomorrow} other {in # days}}"
For more dynamic cases (e.g., "3 minutes ago"), use the browser's built-in Intl.RelativeTimeFormat:
const rtf = new Intl.RelativeTimeFormat('en', { numeric: 'auto' });
rtf.format(-1, 'day'); // "yesterday"
rtf.format(3, 'hour'); // "in 3 hours"
rtf.format(-5, 'minute'); // "5 minutes ago"
This is a very common pattern in modern web apps: chat timestamps, notification feeds, and booking confirmations all benefit from relative time.
ICU vs other formats
ICU message format is widely used in software localization, but there are other formats that can be used for similar purposes.
| Feature | ICU Message Format | Fluent | FormatJS | i18next |
|---|---|---|---|---|
| Plural support | Yes | Yes | Yes | Yes |
| Gender/select support | Yes | Yes | Yes | Yes (via i18next-icu) |
| Type-safe messages | Via external tools | No | Partial | Via typesafe-i18n |
| Adoption | Very high | Low | High | Very high |
| Ecosystem/Plugins | Medium | Low | Medium | Very high |
| Learning curve | Medium | High | Medium | Low |
Notes:
- ICU Message Format is perfect for complex plural/gender/date/number formatting
- Fluent focuses on readability and natural language patterns
- FormatJS with react-intl builds on ICU for JavaScript frameworks
- i18next is a popular i18n framework for JavaScript and beyond. With the i18next-icu plugin, you get full ICU select/plural support, giving you the best of both worlds
- Type-safety tip: If you use TypeScript, check out typesafe-i18n or next-intl for compile-time validation of your ICU messages. Catching
{roomsNumber}typos at build time beats finding them in production
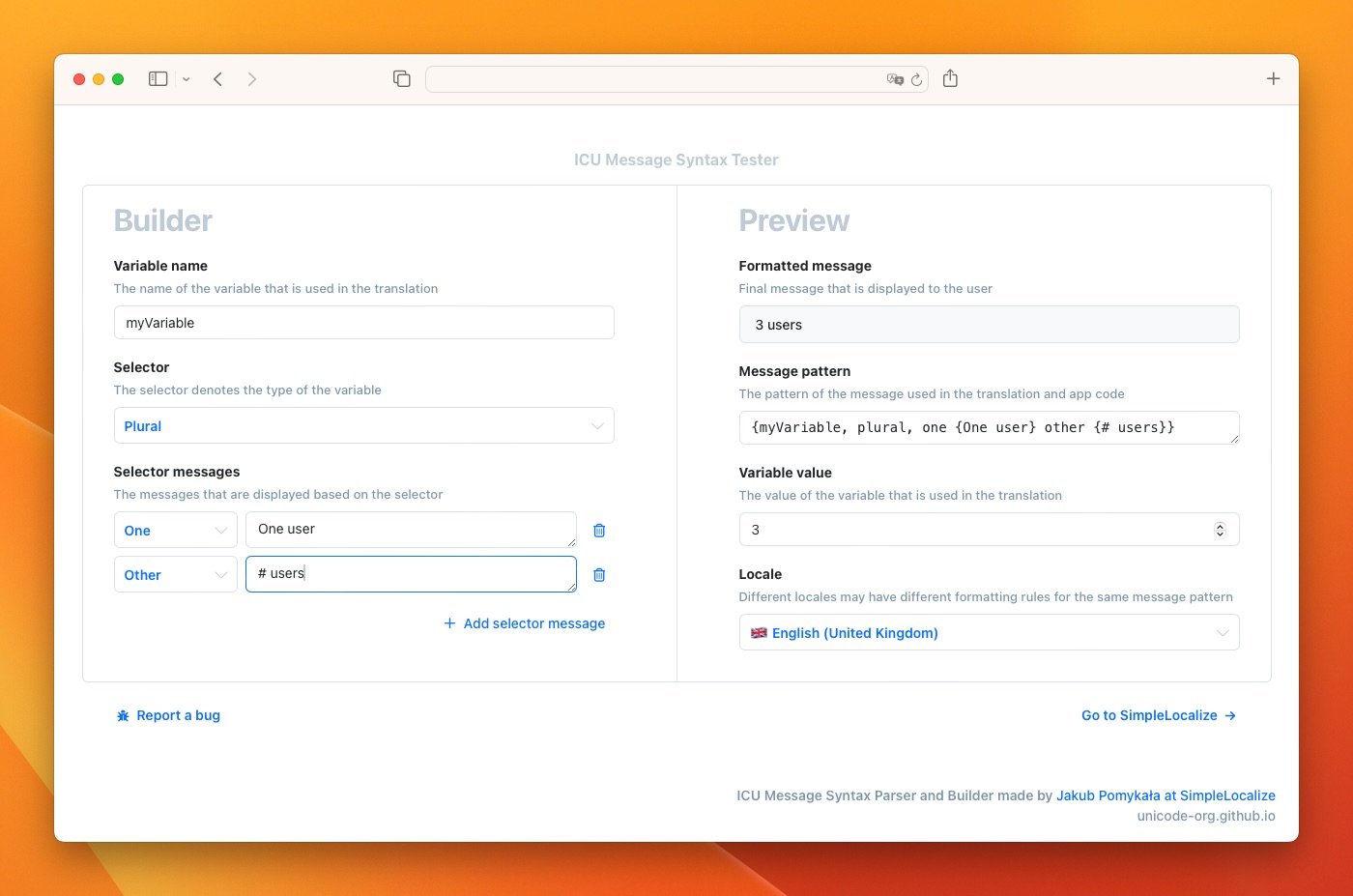
ICU Message Syntax Tester
To test ICU message syntax, you can use the ICU Message Syntax Tester. It is a tool that allows you to test ICU message syntax and see how it will be formatted in different languages.
You can enter a message with ICU syntax and see how it will be formatted for different locales. This can help you ensure that your ICU messages are formatted correctly and will display correctly in different languages.
Conclusion
To sum up, ICU is a powerful library that provides support for the world's languages, scripts, and locales. It provides a set of APIs and data files that enable applications to work with any language. ICU helps applications to display text correctly in different languages, formats date and time according to local custom, and sort text according to local conventions.
Key benefits of ICU include:
- Unicode support: Handles text consistently across many languages and scripts.
- Extensive locale data: Offers rich locale-specific information like date, number, and language formats.
- Platform-independent: Works across multiple platforms and languages, making integration easy.
- Robust and Reliable: Widely used and maintained by the Unicode Consortium, ensuring robustness.
- Customizable: Allows tailoring of locale data to meet specific needs.
Together, these features make ICU an essential tool for developers who want to internationalize and localize software efficiently and accurately.
Working with i18n content
Software localization brings many challenges for all involved teams, from developers, to translators and managers. The main issue is usually localization quality.
Using ICU messages for multilingual content helps address this by providing detailed context and coverage of language variations. This leads to higher translation quality and better user satisfaction.
SimpleLocalize simplifies translation management with developer and translator-friendly tools and easy integrations. It automates workflows and offers a centralized platform for your entire team.
How translators see ICU: SimpleLocalize turns complex syntax into simple input fields.
Get started for free and import your translation files to get started with translation management.
Useful links
For more information about ICU, you can check the following resources:
- ICU official homepage or GitHub repository
- ICU documentation
- Unicode CLDR specs
- Number formatting in JavaScript
- ICU date symbols table
- ICU Message Syntax Tester
- Java internationalization guide


")


